Is it possible to train AI models to accurately classify headline-level text such as tweets, news headlines or company announcements?
Our business context at Robotic Online Intelligence (ROI) is about filtering external information for the human consumption in finance and business. In particular, when it comes to dealing with short-text inputs such as tweets, news or company disclosure headlines. The idea is to operate at the headline level without the need to access or process the full content.
The use cases in this context range from e.g. identifying signals of events that might affect a company share price, to the search for particular data points, to determining what an analyst or an executive should spend time reading or be alerted to specific developments.
Automation of such filters can save time and give an information edge.
In addition to the keywords, expressions and Regex (regular expressions) we have been using for tagging/classification and scoring, we have also been developing a neural network to augment the deterministic methods. The short text length brings out extra challenges, with limited context available, and for machine learning, the more data, the better.
There are some great and readily available NLP (Natural Language Processing) models or algorithms that can be used for text classification, for example GPT-3, BRAT, BERT, and XLNet. However, there is no single best algorithm that would outperform across different contexts. An algorithm which is good at analyzing sentiment in the feed of tweets about a company is not guaranteed to perform well in the analysis of the stock market news sentiment. An algorithm may only perform well when there is a huge amount of training data. For example, the ConveRT model outperforms Google’s BERT when there aren’t many data points. There are a number of algorithms which can be used for short text classification, for example, fastText and LibShortText. However, some of these may require substantial CPU and RAM hardware resources to train the model.
With that in mind, at Robotic Online Intelligence, our strategy has been to integrate multiple neural network techniques to leverage the power of each of them. Our network has multiple layers, two of which are a convolutional neural network (CNN) and long short-term memory (LSTM).
We use word embedding as a common technique to project words into a ‘digital space’ and represent text content through vectors of real numbers, where words used in a similar way get located close to each other. For example, “dog” is closer to “cat” than “science”.
Another technique we are using is convolutional neural networks (CNN), a type of deep learning algorithm which is mostly used in image processing to capture information from surrounding pixels. It can, however, also be applied to text classification, to detect patterns and capture information from the neighbouring words.
Besides the above two, we also use long short-term memory (LSTM) architecture. LSTM is a type of recurrent neural network architecture, often applied to the time series data. The word “memory” in LSTM’s name is from the feedback connections in its network architecture. When applying LSTM to a sentence of words, it can selectively “remember” or “forget” the previous words information.
The architecture we have been using at Robotic Online Intelligence:
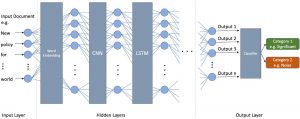
We have built our neural network architecture applying the above well-established techniques, optimising a range of parameters for our specific use case. We aimed for a balance between accuracy and resource cost (time and hardware resources).
The result has been very encouraging so far, albeit limited to several narrowly defined domains.
For example, one model helps determine what the ‘top reads’ should be in a specific domain of China Property or central banks disclosure. In another case, our clients use a model to eliminate irrelevant content from the larger content set to be processed by their analysts looking for particular data points, where we can save 30-50% of the analysts’ time by removing the noise, while losing only 0.9-3% of ‘good items’. In a different example, a model helps determine whether the content meets a certain threshold of relevance to be included in distribution to clients.
When we experimented with a model to detect sentiment, however, a simple bag-of-words approach yielded much better results.
We also found that the traditional keywords and our favorite regular expressions can greatly work together with such AI models.
The AI model itself is one thing and the practical use of it another. Consider the trade-offs between accuracy and the computing or time resources needed to achieve certain accuracy. “We need to re-train the model, see you in a few days” might not work in practice. Or the understanding of what drives the model. Or the actual user of the output – and how the results of the AI’s work integrate into a workflow of an analyst or an executive – if we focus on the humans as the end users. The practical aspects of labelling the data matter too, including the ability to review and test consistency of data labelling done by the analysts.
We have therefore integrated all the AI elements above into the Kubro(TM) SaaS platform. That includes the toolkit for labelling the data, training the model, and using the model within the Kubro(TM) platform and combining it with the keywords and regex. The architecture is not restricted to any language, and has been used on content in e.g. English, Chinese, French and other languages.
As each user can train their own models and the training process shares the same hardware resources, on average it takes around 3 minutes to train a neural network model using 2,000 labelled training data, using moderate level of hardware resources. When using the model, it just takes milliseconds to load and run on new content.
ROI’s Kubro(TM) provides on a SaaS basis an intuitive and easy to use web interface for users to label and train their own models and apply the models as filters on content collections:
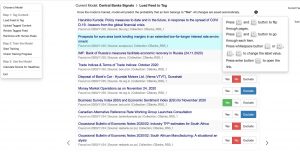
The models can then be used throughout the system to apply to specific content sets, incl. for example robo-reports:
![]()
The models can serve as a filter for picking the ‘top items’ in the Signallium™ market intelligence platform, an example for China Property:

That very practical aspect of deploying neural networks remains our focus, seeking cost-efficient yet substantial improvements rather than chasing the 99.9% perfection.
The tools and the neural network are fully ready for use on our Kubro™ platform as well as via customised deployments.
Robert Ciemniak is the Founder-CEO of Robotic Online Intelligence Ltd, based in Hong Kong.